Operators
Corresponding
Example 1
append initial line to mt_header assigning field-symbol(<fs_header>).
<fs_header> = corresponding #( <fs_lclic> except datab datbi ).
Example 2
sort mt_bdata by odnnr.
loop at mt_report into data(ls_report).
read table mt_bdata into data(ls_bdata)
with key odnnr = ls_report-odnnr
binary search.
if lv_has_tibnb = abap_true and
sy-subrc ne 0.
continue.
endif.
append initial line to mt_data
assigning field-symbol(<fs_data>).
<fs_data> = corresponding #( base ( <fs_data> ) ls_report ).
<fs_data> = corresponding #( base ( <fs_data> ) ls_bdata ).
clear ls_bdata.
endloop.
ALPHA = IN / ALPHA = OUT
The ALPHA formatting option was introduced and completely replaces the two function modules CONVERSION_EXIT_ALPHA_INPUT and CONVERSION_EXIT_ALPHA_OUTPUT. Now you can add or remove leading zeros with this one .
Below is the syntax for the ALPHA Embedded Expressions.
ALPHA = IN|OUT|RAW|(val)]
ls_itemx-preq_item = ls_item_bapi-preq_item = |{ <fs_item>-preq_item ALPHA = IN }|.
REDUCE
A constructor expression with the reduction operator REDUCE creates a result of a data type specified using type from one or more iteration expressions. The following can be specified for type:
A non-generic data type dtype.
The # character as a symbol for the operand type.
If the data type required in an operand position is unique and known completely, this type is used.
If the operand type is not known completely, the type of the first declaration after INIT (which is always known) is used, except if the constructor expression is passed to an actual parameter with a generically typed formal parameter.
If the constructor expression is passed to an actual parameter with a generically typed formal parameter, the operand type is derived in accordance with special rules.
VALUE
A constructor expression with the value operator VALUE creates a result of a data type specified using type. The following can be specified for type:
A non-generic data type dtype.
Exceptions to this rule are:
When an initial value VALUE #( ) is passed to a generically typed formal parameter, the type is derived from the generic type.
The operand can be evaluated after BASE when a structure or an internal table is constructed.
When used for a single table expression VALUE #( table_expo ).
Addition 1
... BASE itab
Effect
An addition, BASE, followed by an internal table, itab, can be specified in front of the lines that you want to insert. This is a functional operand position. The row type of itab must be convertible to the row type of the return value. If BASE is specified, the content of itab is assigned to the return value before the individual rows are inserted. If the character is specified for the type of the return value and the type cannot be determined from the operand position of the constructor expression, the type of itab is used for this expression (if identifiable).
Notes
◾ If the addition BASE is not specified, only new content of tables can be constructed with the value operator and not enhanced. If the same table is specified after BASE to which the constructor expression is assigned, further rows can be inserted in this table (otherwise, all rows will be refreshed to initial before inserting new lines.
◾ If the target table is specified as itab after BASE in an assignment to an existing internal table, no assignment takes place before line_spec is evaluated, and the target table just keeps its value instead.
Syntax
Variables: VALUE dtype|#( )
Structures: VALUE dtype|#( comp1 = a1 comp2 = a2 … )
Tables: VALUE dtype|#( ( … ) ( … ) … ) …
Create new data for work area
TYPES: BEGIN OF ty_columns1, “Simple structure
cols1 TYPE i,
cols2 TYPE i,
END OF ty_columns1.
TYPES: BEGIN OF ty_columnns2, “Nested structure
coln1 TYPE i,
coln2 TYPE ty_columns1,
END OF ty_columns2.
data(struct_nest) = VALUE ty_columns2( coln1 = 1
coln2-cols1 = 1
coln2-cols2 = 2 ).
OR
data(struct_nest) = VALUE ty_columns2( coln1 = 1
coln2 = VALUE #( cols1 = 1
cols2 = 2 )
).
Use # if it is not inline declaration
Note: there is always space between open bracket and its elements.
loop at lt_tj02 into data(ls_tj02).
r_stat = value #( base r_stat ( sign = 'I' option = 'EQ' low = ls_tj02-istat ) ) .
endloop.
Pay attention to the space between r_stat and open bracket
Creating new data of internal tables
Elementary line type:
TYPES t_itab TYPE TABLE OF i WITH EMPTY KEY.
DATA itab TYPE t_itab.
itab = VALUE #( ( ) ( 1 ) ( 2 ) ).
Structured line type (RANGES table):
DATA itab TYPE RANGE OF i.
itab = VALUE #( sign = ‘I’ option = ‘BT’ ( low = 1 high = 10 )
( low = 21 high = 30 )
( low = 41 high = 50 )
option = ‘GE’ ( low = 61 )
) .
Move Data between Internal Tables
MOVE-CORRESPONDING for Internal Tables
You can use MOVE-CORRESPONDING not only for structures but also for internal tables now. Components of the same name are assigned row by row. New additions EXPANDING NESTED TABLES and KEEPING TARGET LINES allow to resolve tabular components of structures and to append lines instead of overwriting existing lines.
Example
MOVE-CORRESPONDING itab1 TO itab2 EXPANDING NESTED TABLES
KEEPING TARGET LINES.
Additions MAPPING and EXCEPT
MAPPING allows you to map fields with non-identically named components to qualify for the data transfer.
… MAPPING t1 = s1 t2 = s2
EXCEPT allows you to list fields that must be excluded from the data transfer
… EXCEPT {t1 t2 …}
For … in (Table Comprehensions)
A new FOR sub expression for constructor expressions with operators NEW and VALUE allows reading existing internal tables and to construct new tabular contents from the lines read.
Example 1
Construction of an internal table lt_lips from lines and columns of an internal table lt_vgbel. You can of course also use the CORRESPONDING operator to construct the lines.
types:
BEGIN OF ty_lips,
ebeln TYPE ekpo-ebeln,
ebelp TYPE ekpo-ebelp,
END OF ty_lips.
TYPES:
ty_t_lips TYPE STANDARD TABLE OF ty_lips WITH DEFAULT KEY.
* must not be generic table (with keys)
DATA(lt_lips) = VALUE ty_t_lips( FOR wa IN lt_vgbel[]
( ebeln = wa-vgbel ebelp = wa-vgpos ) ).
Example 2
types:
ty_gen_tmp_t type table of zgt_gen with default key.
data(lt_gen_tmp) = value ty_gen_tmp_t( for wa in gt_gen
( guid_pr = wa-guid_pr
prvsy = wa-prvsy
attr02a = wa-attr02a ) ).
insert zgt_gen from table @lt_gen_tmp.
select t1~prvsy , t2~guid_pr, t2~prtxt
from zgt_gen as t1 inner join /sapsll/prt as t2
on t1~guid_pr = t2~guid_pr
into table @data(lt_table1).
SQL Statements
CASE Statements In OPEN SQL Queries in ABAP 7.4
One of the new features of ABAP 7.4 is the ability to use CASE statements in Open SQL queries. The code below shows an example of this. In this example there is a field in a local structure named ERNAM, and it should be filled with the literals “NAME1″, “NAME2″, or “NAME3″ respectively, depending on the contents of the database field AUART (DocType).
DATA: ls_vbak TYPE vbak,
ld_vbeln LIKE vbak-vbeln.
PARAMETERS: p_vbeln like vbak-vbeln.
CONSTANTS: lc_name1(5) TYPE c VALUE 'name1',
lc_name2(5) TYPE c VALUE 'name2',
lc_name3(5) TYPE c VALUE 'name3'.
ld_vbeln = p_vbeln.
SELECT vbeln, vbtyp,
CASE
WHEN auart = 'ZAMA' THEN @lc_name1
WHEN auart = 'ZACR' THEN @lc_name2
ELSE @lc_name3
END AS ernam
FROM vbak
WHERE vbeln = @ld_vbeln
INTO CORRESPONDING FIELDS of @ls_vbak.
ENDSELECT.
SELECT vbeln, vbtyp,
CASE
WHEN auart = 'ZAMA' THEN @lc_name1
WHEN auart = 'ZACR' THEN @lc_name2
ELSE @lc_name3
END AS ernam
FROM vbak
WHERE vbeln = @ld_vbeln
INTO CORRESPONDING FIELDS of @ls_vbak.
ENDSELECT.
Please make note that you have to put an @ symbol in front of your ABAP variables (or constants) when using new features, such as CASE, in order to let the compiler know that you are not talking about a field in the database. (This is called “Escaping” the Host Variable).
Why did I use this as my first example? Surely you have used the CASE statement on data AFTER you have retrieved it. So what have we gained or even done by placing the CASE inside the SELECT? Well, what the CASE statement has allowed you to do is outsource the conditional logic to the database, as opposed to performing the CASE on the application server.
If you are unfamiliar with coding ABAP on HANA, the paradigm shift of pushing logic down into the SAP HANA database to be processed is new, but can result in huge performance improvements. While this example is not HANA specific, it does introduce you to the “concept of pushing code down” to the database layer. Something in the past we have been told to avoid. The new paradigm in ABAP is “Code-to-Data”. We will learn to create VALUE by optimizing the backend DBMS (HANA).
Perform Calculations within SQL Statements in ABAP 7.4
Another feature that is new to release 7.4 is the ability to perform arithmetic operations inside of SQL statements. Before 7.4 you had to select the data first, then you could perform calculations on it. This is best explained with an example. Let’s say we are selecting against table SFLIGHT. We want all rows for United Airlines connection id 941. For each row, we will add together the total occupied seats in Business Class and First Class, then we will multiply that by price and store the result in field paymentsum of our internal table.
DATA: lt_sflight TYPE TABLE OF sflight.
CONSTANTS: lc_carrid TYPE s_carr_id VALUE 'UA',
lc_connid TYPE s_conn_id VALUE '941'.
SELECT carrid, connid, price, seatsocc_b, seatsocc_f,
( ( seatsocc_b + seatsocc_f ) ) * price AS paymentsum
FROM sflight
WHERE carrid = @lc_carrid
AND connid = @lc_connid
INTO CORRESPONDING FIELDS of TABLE @lt_sflight.
In-Line Declarations within SQL Statements in ABAP 7.4
ABAP 7.4 has removed the need to create the data declaration for an internal table or structure. In prior versions of ABAP, if you declared a TYPE and then suddenly wanted to retrieve an extra field in your SELECT, then you would need to make the change in two places: in the TYPE definition and in the SELECT statement. In ABAP 7.4, however, you can not only skip the TYPE definition but the internal table declaration as well. An example of this is shown below:
SELECT carrname AS name, carrid AS id
FROM scarr
INTO TABLE @DATA(result).
Look at the debugger screen-shot below:

As you can see, the table is created at the instant the database is accessed, and the format or ABAP TYPE of the table is taken from the types of the data fields you are retrieving.
This also works for structures if you are doing a SELECT on multiple database fields. The column name can also be influenced in the target internal table using the AS <variable> construct. So in the example below, in the internal table result, CARRNAME will be called NAME and CARRID will be called ID.
SELECT SINGLE carrname AS name, carrid AS id
FROM scarr
WHERE carrid = @id
INTO @DATA(result).
INNER Join Column Specification in ABAP 7.4
As developers we (you) probably use Inner Joins frequently. In ABAP 7.4 we can utilize the ASTERISK in much the same way we can use it in a SELECT *. In the SELECT list, you can now specify all columns of a data source using the new syntax data_source~* (see below:)
SELECT scarr~carrname, spfli~*, scarr~url
FROM scarr INNER JOIN spfli ON scarr~carrid = spfli~carrid
INTO TABLE @DATA(result).
Take a look at the Debugger screenshot below:

You can see that SPFLI has been added to the table RESULT. Please remember to address the data for SPFLI you would need to code as follows…
RESULT[n]-SPFLI-data_element
Also, please, please, please… be mindful when using the asterisk. It acts just like the wild card in SELECT * and can impact performance if you really didn’t want all of the columns.
Once again, I’d like to mention Paul Hardy’s excellent book ABAP® to the Future. Click the image below to pick up a copy, it will definitely become your go-to reference as the new features of ABAP are rolled out where you work!
GROUP BY in Loop
loop at lt_input into data(ls_input)
group by ( prueflos = ls_input-prueflos
inspoper = ls_input-inspoper
count = group size )
ascending
assigning field-symbol(<group>).
loop at group <group> assigning field-symbol(<fs_data>).
endloop.
endloop.
Looks like dreaded nested LOOPs, but it isn’t quite that – no quadratic behavior! What happens here is that the first LOOP statement is executed over all internal table lines in one go and the new GROUP BY addition groups the lines. Technically, the lines are bound internally to a group that belongs to a group key that is specified behind GROUP BY.
The group key is calculated for each loop pass. And the best is, it need not be as simple as using only column values, but you can use any expressions here that normally depend on the contents of the current line, e.g. comparisons, method calls, …. The LOOP body is not evaluated in this phase!
Only after the grouping phase, the LOOP body is evaluated. Now a second (but not nested) loop is carried out over the groups constructed in the first phase. Inside this group loop you can access the group using the field symbol <group> that is assigned to the group in the above example. If you want to access the members of the group, you can use the new LOOP AT GROUP statement, which enables a member loop within the group loop. In the example, the members are inserted into a member table and displayed.
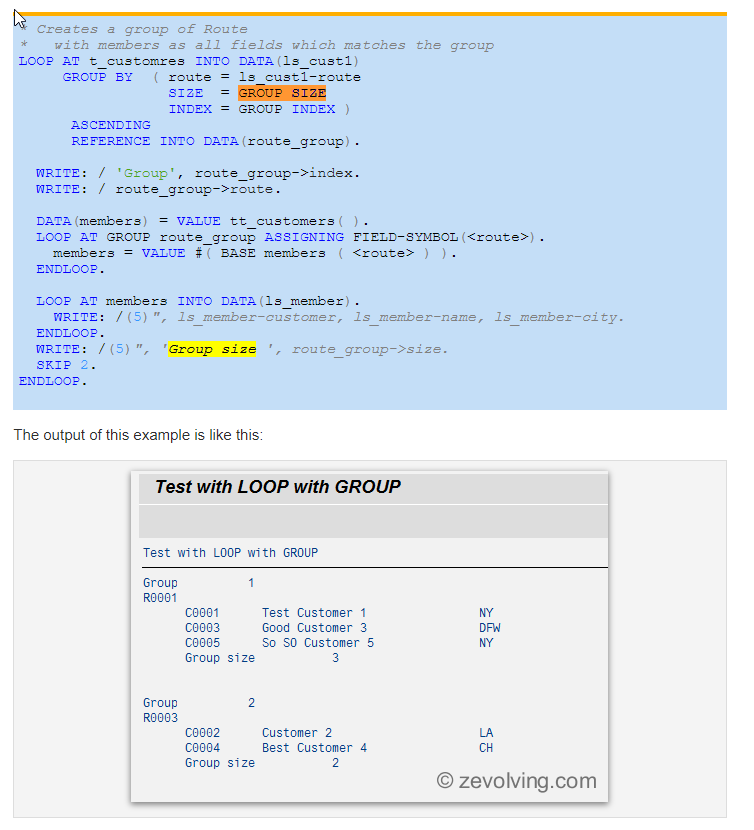
Example 2 – Usage of MEMBERS, SIZE and INDEX
The 2nd phase of the GROUP BY is the access the members of the LOOP. To get the members of the group, we need to LOOP AT GROUP within the main LOOP. This inner LOOP needs to use the group result to get the members. The new BASE addition of VALUE will provide all the field values for non group fields. More on BASE in upcoming articles.
There are two inbuilt additions for the GROUP BY key.
SIZE – This would have the number of rows in that group
INDEX – Would be index number of the group, starting with 1.
When the single field is used to make the key, the result would be created as the single field as shown in earlier example. When there are more than one field, the automatic variable would contain all those fields, as in this example.
Example
Here another example, where the group key is evaluated from method calls:
LOOP AT flights INTO DATA(wa)
GROUP BY ( tz_from = get_time_zone( wa-airpfrom )
tz_to = get_time_zone( wa-airpto ) )
ASSIGNING FIELD-SYMBOL(<group>).
…
ENDLOOP.
Of course, there is also expression enabled syntax for grouping internal tables.
In a first step, we get rid of LOOP AT GROUP by replacing it with a FOR expression:
DATA members LIKE flights.
LOOP AT flights INTO DATA(flight)
GROUP BY ( carrier = flight-carrid
cityfr = flight-cityfrom )
ASCENDING
ASSIGNING FIELD-SYMBOL(<group>).
members = VALUE #( FOR m IN GROUP <group> ( m ) ).
cl_demo_output=>write( members ).
ENDLOOP.
cl_demo_output=>display( ).
The IN GROUP is a new addition to FOR. Second, away with the outer LOOP:
TYPES t_flights LIKE flights.
DATA out TYPE REF TO if_demo_output.
out = REDUCE #( INIT o = cl_demo_output=>new( )
FOR GROUPS <group> OF flight IN flights
GROUP BY ( carrier = flight-carrid cityfr = flight-cityfrom )
ASCENDING
LET members = VALUE t_flights( FOR m IN GROUP <group> ( m ) ) IN
NEXT o = o->write( members ) ).
out->display( ).
FOR GROUPS is another new FOR variant. Believe me, it does the same as the variants above. But for reasons of readability, the combination of LOOP AT GROUP with a FOR IN GROUP within might be the preferable one, at least for this example.
Read internal table in new way
Using new ABAP statement to access internal tables, the code can be something like that:
my_field_1 = t_table[ field = value ]-field_1.
try.
<fs_vbap>-ebeln = lt_ebkn[ vbeln = <fs_vbap>-vbeln vbelp = <fs_vbap>-posnr ]-ebeln.
<fs_vbap>-ebelp = lt_ebkn[ vbeln = <fs_vbap>-vbeln vbelp = <fs_vbap>-posnr ]-ebelp.
catch cx_sy_itab_line_not_found.
Endtry.
2nd example:

If a table expression fails to find a line it will raise exception CX_SY_ITAB_LINE_NOT_FOUND, so really that notation should actually be:
TRY.
lv_order = lt_aufk[ aedat = sy-datum ]-aufnr.
CATCH cx_sy_itab_line_not_found.
ENDTRY.
About the exception:
There are ways around it.
If the specified row is not found, a handleable expression of the class CX_SY_ITAB_LINE_NOT_FOUND is raised in all operand positions, except when
a default value is specified in the definition of the type of the result,
a table expression is used in the statement ASSIGN, where sy-subrc is set to the value 4,
when used in the predicate function line_exists, where the logical value "false" is returned,
when used in the table function line_index, where the value 0 is returned.
Default values for table expressions
Neat if you're on SP08 or higher already:
Table expressions itab[ ...] cannot support sy-subrc. Up to now, an exception was raised anytime if a table line specified in the square brackets could not be found. Not everybody liked this behavior.
As a workaround, you can place a table expression inside a VALUE or REF expression, that contains a OPTIONAL or DEFAULT addition. If a line is not found, the OPTIONAL addition returns an initial line while the DEFAULT addition returns a given value, that can be specified as an expression, especially another table expression.
TYPES:
BEGIN OF line,
id TYPE i,
value TYPE string,
END OF line,
itab TYPE SORTED TABLE OF line WITH UNIQUE KEY id.
DATA(def) = VALUE line( id = 0 value = `not found` ).
...
DATA(result) = VALUE #( itab[ id = ... ] DEFAULT def ).
Another workaround
try.
l_cons_flag = lt_t434r[ rules = l_rules ]-cons_hnd_bf.
catch cx_sy_itab_line_not_found.
Clear l_cons_flag.
endtry.